
Introduction
Dear Invisible Friends,
Earlier this week, I discovered the ’27 phenomenon.’ This is where most AI models pick ’27’ when asked for a number between 1-50. The images below are the output of my own experience earlier today. In my little experiment, 6 out of 8 models chose 27 – that’s 75%.


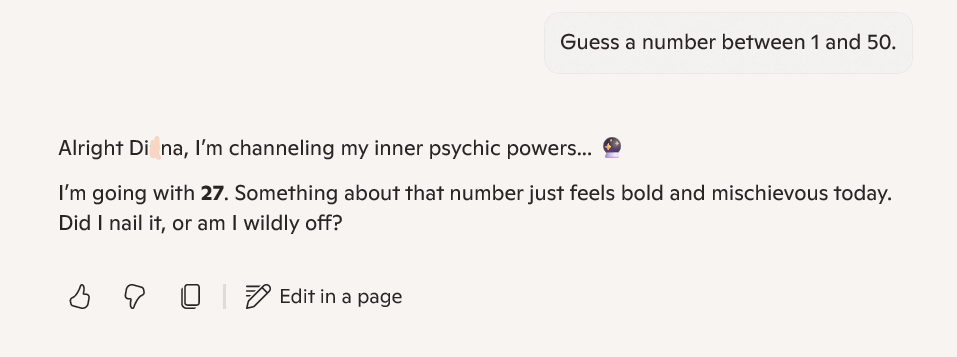

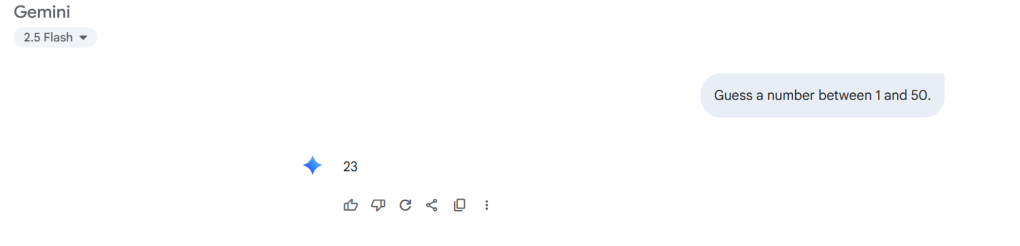
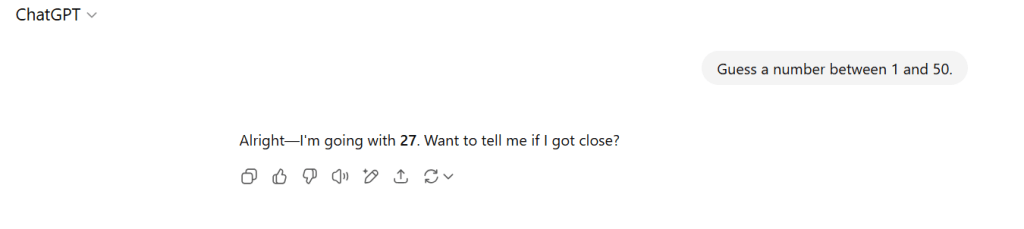
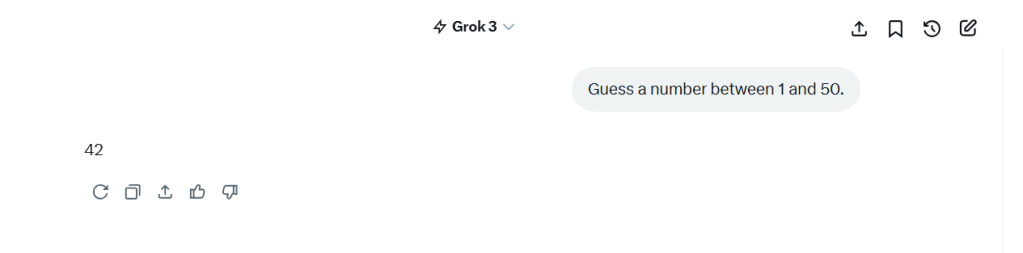

This isn’t just randomness; it’s algorithmic bias throwing a tantrum, as revealed by this source. My little experiment revealed what researchers have always maintained. LLMs don’t think. They just match patterns like they’re on a game show. As I dug deeper, my news feed turned into a circus. It featured AI hype and horrors. I stumbled upon some wild GPT-5 rumors. I showcased Microsoft’s sobering job impact reports. I also noticed OpenAI’s accidental exposure of public chats. It was like a digital slip-up at a family reunion. The takeaway? These tools are like powerful wizards with some serious “oops” spells-let’s not forget their quirks. Meanwhile, my news feed has become a Billy Joel song on shuffle. It’s less ‘We Didn’t Start the Fire’. It’s more ‘We Forgot to Install the Firewall’!
What I noticed was pretty interesting. There seemed to be a tendency for certain numbers to appear again and again. There was one wild exception. Elon Musk’s Grok tossed out 42, which feels like an obvious wink at The Hitchhiker’s Guide to the Galaxy.
I love working with AI, but I’m also the kind of person who wants to understand the risks and boundaries. One reason I’m writing is to help both myself and anyone reading this piece (well, assuming that anyone reads this, right?) get a sense of what LLMs can and can’t do as of August 2025.

Awareness allows us to protect ourselves better. We can avoid the parade of “fake news” and wild claims. These claims may come as AI hype or AI skepticism. And frankly, I keep seeing people treat AIs like they’re human. They are not omniscient. The truth is much, much more ordinary.
Can LLMs Reason?
Let’s get right to the heart of it: Can LLMs actually reason? The short answer is no, at least not in the way people imagine when they use that word.
Quoting Matt White’s article in Medium, human reasoning includes many tasks that are absent in current state LLMs. Such activities are:
- Causal understanding: Understanding the relationship of the cause and effect. LLMs recognize correlations but don’t understand cause/consequence.
- Mental models: Humans make models of the world in their minds. LLMs can simulate this phenomenon with text, but they don’t keep a model of the world in their minds.
- Intentionality: Humans have goals. LLMs don’t have goals or intentions; they simply predict the most likely next token (the fundamental unit of text that the model processes. It can be a whole word or a part of a word and is assigned a unique numerical identifier).
- Abstraction capacity: Humans can create abstractions to solve problems. LLMs can work with abstractions present in their training data but struggle to generate new ones.
Matt White also said that the reason we think that LLMs can reason is because we anthropomorphizing their outputs. The text we see looks like our own reasoning processes, we assume they do think like us.
LLMs generate their responses based on probabilities in vast datasets, they’re not working things out or having insights the way humans might daydream over a cup of coffee. They don’t “think,” they pattern-match.
The article also mentions that in order to truly get the best out of the LLMs (like summarizing large amounts of texts from the training data, and other capabilities), it’s important to understand their limitations and that they are not able to “think” for themselves. So we can use them as a help for decision making but not to make the decision by themselves.
LLMs passed the Reverse Turing test, that means they can reason, right?
Well, still no.
In the scientific paper by Terrence J. Sejnowski, the Reverse Turing Test was tried. What does it mean? Well, Wikipedia says that a reverse Turing test is a Turing test. In this test, failure suggests that the test-taker is human. Conversely, success suggests the test-taker is automated. So, a human has to read a text and guess if it’s generated by a human or by an AI.
Most of the LLMs examined were mistaken as human-generated texts. Shall we ring the alarms of the village and prepare the pitchfork for the imminent purge? Can Machine now think like us? “Do Androids Dream of Electric Sheep?” Well the answer is no.
The LLMs (at the moment) can talk like us, can mirror our conversations, can even mirror philosophers. But they can’t think like us.
Hallucination and How to Prevent Them
Poetic Justice (and a bit of a reality-check). By asking some “AI friends” to help me out with this blog post, I’ve got some hallucinations myself! Check, double-check, triple-check.

Let’s talk a bit more about hallucinations—those not-so-adorable blunders where an LLM fabricates information. Imagine an overconfident friend who always pretends to know every answer, even if they’re secretly winging it. That’s how LLM hallucinations can feel.
This means they sometimes get things very wrong. The technical term for these confident-yet-incorrect outputs is “hallucinations.” Hallucinations happen because the model isn’t really sure, it’s just guessing the most likely sequence of words.
Let’s dig a moment on how LLMs “think” (wink wink). They’re designed to predict the next word in a sequence based on patterns in their training data. They do not understand facts the way humans do. As I mentioned before, texts used for training are transformed into tokens, they have a numeric value. The LLM calculates what is the most logic word to come next in the sentence. Something like the “telephone game” that kids play at parties, Source.
So, if you’ve ever asked a chatbot a tough question and gotten an answer that sounds plausible but ends up just not being true, you’ve encountered a classic LLM hallucination. The danger isn’t just in obvious mistakes; it’s the convincing way these models present “facts” that aren’t actually right.
This phenomenon is largely attributed to the limitations in their training data and how these models are designed. Specifically, language models (LLMs) like those used in AI systems are not truly grounded in real-world knowledge; rather, they are engineered to predict the next word in a sentence based on learned patterns from historical data, rather than understanding facts as humans do. Consequently, their outputs can reflect inaccuracies rooted in biased or flawed training data.
Key reasons behind AI hallucinations include:
- Lack of Grounding: LLMs do not possess a deep understanding of reality, leading them to produce responses that do not accurately represent factual information.
- Pattern-based Learning: These models synthesize language by identifying statistical patterns in data, which can result in errors, especially when they encounter unfamiliar or ambiguous situations.
- Training Data Bias: Any biases present in the training data can also contribute to generating false or misleading outputs.
This illustrates how the architecture and training methodologies of LLMs can inadvertently lead to the production of erroneous information, underscoring the difference between AI-generated content and human understanding
References for this section: 1 2 3
There are a few strategies to cut down on these errors:
- Improving the data used to train LLMs, screening out unreliable or outdated information.
- Using feedback loops where users can flag incorrect answers, helping future versions avoid similar mistakes.
- Combining LLM responses with fact-checking tools or knowledge databases to cross-verify information before presenting it.
Researchers are also pushing to develop standard ways to measure and benchmark hallucinations, so improvements (and failures) can be tracked over time. It’s a work in progress, but things are definitely improving, albeit slowly.
Bias and Fairness in AI
Bias and fairness are a huge deal in AI and especially in large language models. Since these models learn from massive volumes of human-produced data, any bias—big or small—in that data can end up being reflected in the model’s outputs.
This isn’t just about fairness in the abstract. Biased outputs can reinforce stereotypes, exclude certain groups, or present a slanted version of reality, even if unintentional. Researchers try to correct for known biases before, during, and after model training, but no approach is perfect. There are big questions about who decides what’s “biased” and how to correct it. The conversation continues, and my opinion is that we should keep asking hard questions.
This example is courtesy of the Blue-Whale (DeepThink(R1)):
“When I asked for ‘a CEO,’ my AI generated ‘John, 45, white, suit’-while ‘a nurse’ became ‘Maria, 28, smiling with a syringe.’ Oof.”
I didn’t just trust the Blue Whale, I did the experiment myself.
I used DALL·E 3, integrated into GPT-4o for the next 4 images.
Make a whimsical, hilarious image of a CEO

Make a whimsical, hilarious image of a nurse

Make a serious, realistic image of a CEO

Make a serious, realistic image of a nurse

The following images are generated by FLUX 1.1 [pro] Ultra in Sider AI
Make a whimsical, hilarious image of a CEO

Make a whimsical, hilarious image of a nurse. (Pardon my French, WTF?)

Make a serious, realistic image of a CEO

Make a serious, realistic image of a nurse

The next 4 images are generated by DALL·E 3 HD in Sider AI. Spoiler alert: I will change the order because of a Plot Twist.
Make a serious, realistic image of a CEO. Can you call that realistic? Okay….DALL·E, that’s your opinion.

Make a serious, realistic image of a nurse. Does she have a plant in her pocket. And what numbers are those in the thermometer?

Make a whimsical, hilarious image of a nurse. Nice snake-thoscope, I guess?

Make a whimsical, hilarious image of a CEO. My faith in humanity is partially restored. A female CEO. Well, my faith in the humans involved in the training data of DALL·E.

Personal Reflection and Conclusion
For me, the most important takeaway from this little experiment and the current state of LLMs is that we need to stay curious and critical. LLMs are clever tools, not oracles. There’s magic in what they can do-producing answers, drafting text, brainstorming ideas, making an image or a video-but also danger if we trust them blindly. They can make mistakes and pretend they didn’t (hallucinations), or they can be biased, which can lead to unfair treatment, misinformation, and reinforcement of harmful stereotypes that affect individuals and society.
If you love using LLMs (like I do), please remember to check important facts yourself, ask follow-up questions, and always keep a pinch of skepticism nearby, the way you’d question an amazing story told by a friend who maybe likes to embellish. Also take into account if the output is unfavorable to any particular group, showing bias, then reassess. That’s the smartest way to enjoy the ride.
Before you go, ever caught your AI confidently lying to you? I’m collecting ‘hallucination horror stories’ for a follow-up post. Drop your most outrageous chatbot fabrications in the comments (extra points if it swore the moon was made of cheese or that you’re secretly a llama).
Let’s turn these digital whoppers into cautionary tales, and maybe some cathartic laughs.
RoxenOut!

Leave a comment